| Edge Enhanced Implicit Orientation Learning With Geometric Prior for 6D Pose Estimation |
| Yilin Wen1, Hao Pan2, Lei Yang1, Wenping Wang1 |
| 1The University of Hong Kong, 2Microsoft Research Asia |
| IEEE Robotics and Automation Letters & IROS 2020 |
| |
| Abstract |
|
Estimating 6D poses of rigid objects from RGB images is an important but challenging task. This is especially true for textureless objects with strong symmetry, since they have only sparse visual features to be leveraged for the task and their symmetry leads to pose ambiguity. The implicit encoding of orientations learned by autoencoders has demonstrated its effectiveness in handling such objects without requiring explicit pose labeling. In this paper, we further improve this methodology with two key technical contributions. First, we use edge cues to complement the color images with more discriminative features and reduce the domain gap between the real images for testing and the synthetic ones for training. Second, we enhance the regularity of the implicitly learned pose representations by a self-supervision scheme to enforce the geometric prior that the latent representations of two images presenting nearby rotations should be close too. Our approach achieves the state-of-the-art performance on the T-LESS benchmark in the RGB domain; its evaluation on the LINEMOD dataset also outperforms other synthetically trained approaches. Extensive ablation tests demonstrate the improvements enabled by our technical designs. Our code is publicly available for research use.
|
 |
|
Preprint [PDF]
Code and data [Link]
Supplemental video [ZIP]
Citation
Y. Wen, H. Pan, L. Yang and W. Wang, "Edge Enhanced Implicit Orientation Learning With Geometric Prior for 6D Pose Estimation," in IEEE Robotics and Automation Letters, vol. 5, no. 3, pp. 4931-4938, July 2020, doi: 10.1109/LRA.2020.3005121.
(bibtex)
|
|
| |
| Algorithm overview |
| |
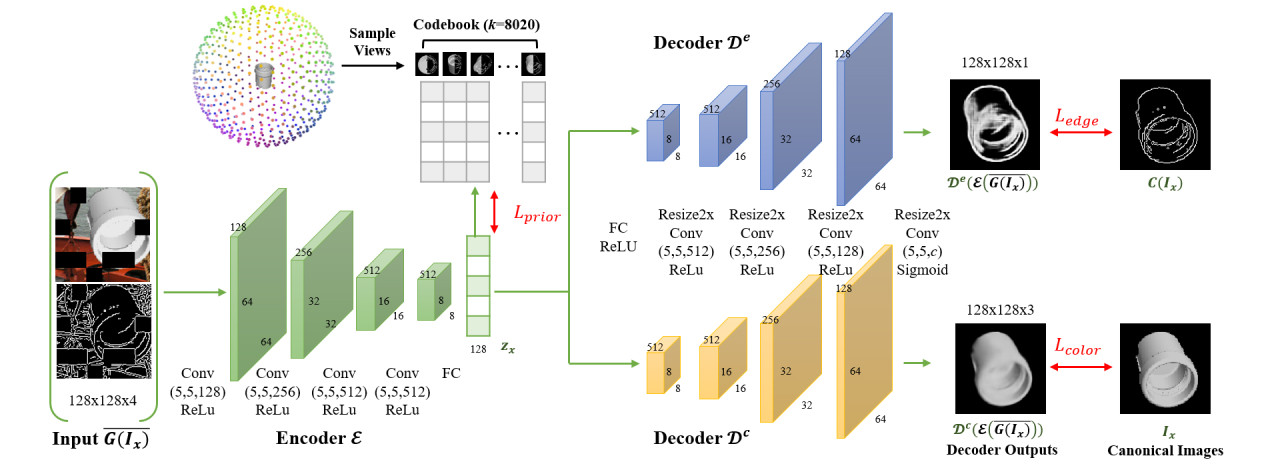 |
|
Training stage pipeline. Given a pair of the augmented color image and its edge map, the encoder maps the concatenated image pair to a code in the latent space. The code is compared against a set of reference codes to impose the geometry prior of the rotation space. Meanwhile, the code is passed through the color and edge decoders to reconstruct the canonical color image (lower branch) and edge map (upper branch), respectively. The reconstruction loss and the geometric prior loss together help the autoencoder to learn an implicit orientation encoding that is more aware of the discriminative edge cues and closer to the rotation space geometry.
|
| |
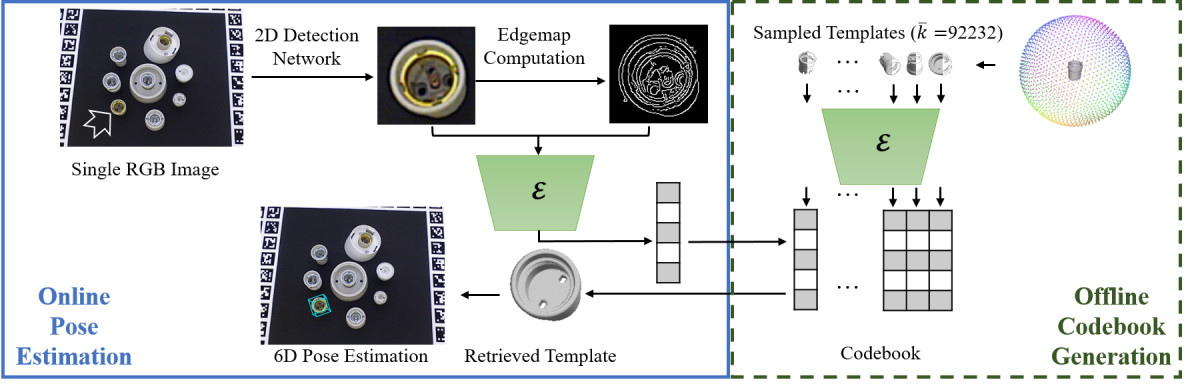 |
|
Test stage pipeline. Given a query RGB image and the object of interest as input, the object in the image is detected by a 2D detector. The detected object region is cropped and resized to feed to the trained encoder. Using the offline generated codebook consisting of encodings of the representative rotations, we estimate the rotation of the query instance via nearest code retrieval, and infer the translation based on the bounding box scale ratio between the retrieved pose template and the detected 2D bounding box.
|
| |
| |
| |
| |
| ©Hao Pan. Last update: Aug 6, 2020. |