| PFCNN: Convolutional Neural Networks on 3D Surfaces Using Parallel Frames |
|
Yuqi Yang1,3,
Shilin Liu2,3,
Hao Pan3,
Yang Liu3,
Xin Tong3
|
|
1Tsinghua University,
2University of Science and Technology of China,
3Microsoft Research Asia |
| The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2020 |
| |
| Abstract |
|
Surface meshes are widely used shape representations and capture finer geometry data than point clouds or volumetric grids, but are challenging to apply CNNs directly due to their non-Euclidean structure. We use parallel frames on surface to define PFCNNs that enable effective feature learning on surface meshes by mimicking standard convolutions faithfully. In particular, the convolution of PFCNN not only maps local surface patches onto flat tangent planes, but also aligns the tangent planes such that they locally form a flat Euclidean structure, thus enabling recovery of standard convolutions. The alignment is achieved by the tool of locally flat connections borrowed from discrete differential geometry, which can be efficiently encoded and computed by parallel frame fields. In addition, the lack of canonical axis on surface is handled by sampling with the frame directions. Experiments show that for tasks including classification, segmentation and registration on deformable geometric domains, as well as semantic scene segmentation on rigid domains, PFCNNs achieve robust and superior performances without using sophisticated input features than state-of-the-art surface based CNNs.
|
 |
|
Paper [PDF]
Code and data [Link]
Citation
Yuqi Yang, Shilin Liu, Hao Pan, Yang Liu, and Xin Tong.
PFCNN: Convolutional Neural Networks on 3D Surfaces Using Parallel Frames. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2020.
(bibtex)
|
|
| |
| Method |
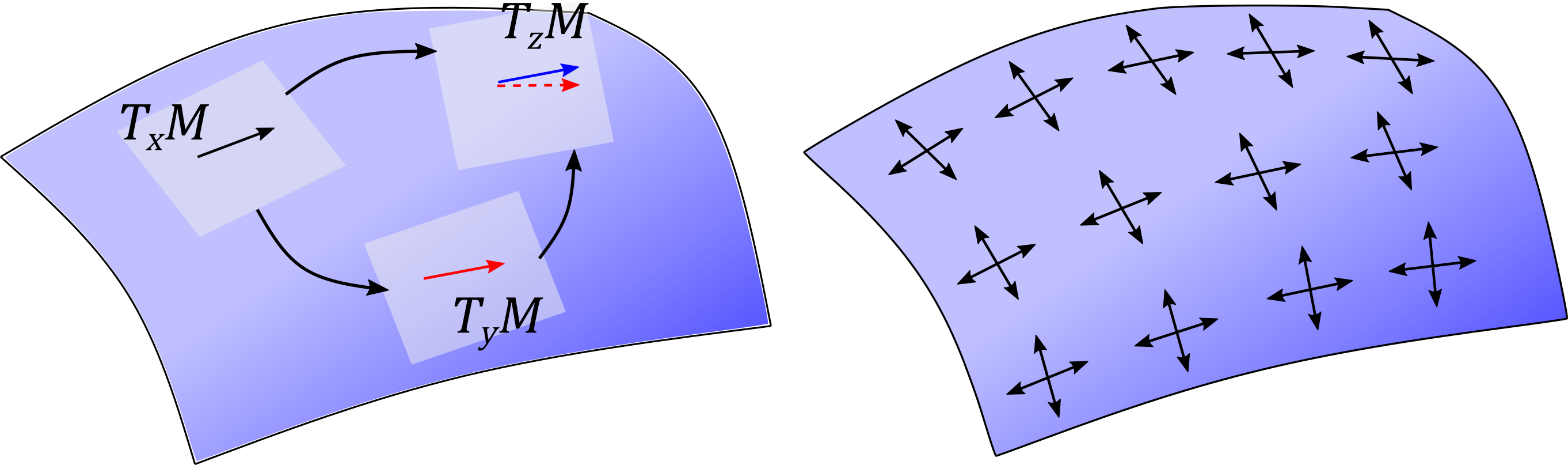 |
|
For patch-based surface CNNs, the key problem is how to align the tangent spaces of different surface points. Left: the parallel transport is path-dependent and maps the vector in TxM directly to the blue one in TzM but to the red dashed one by going through TyM. Right: by building a flat connection encoded by the parallel 4-direction frame field, our approach has path-independent translation as in image domain.
|
| |
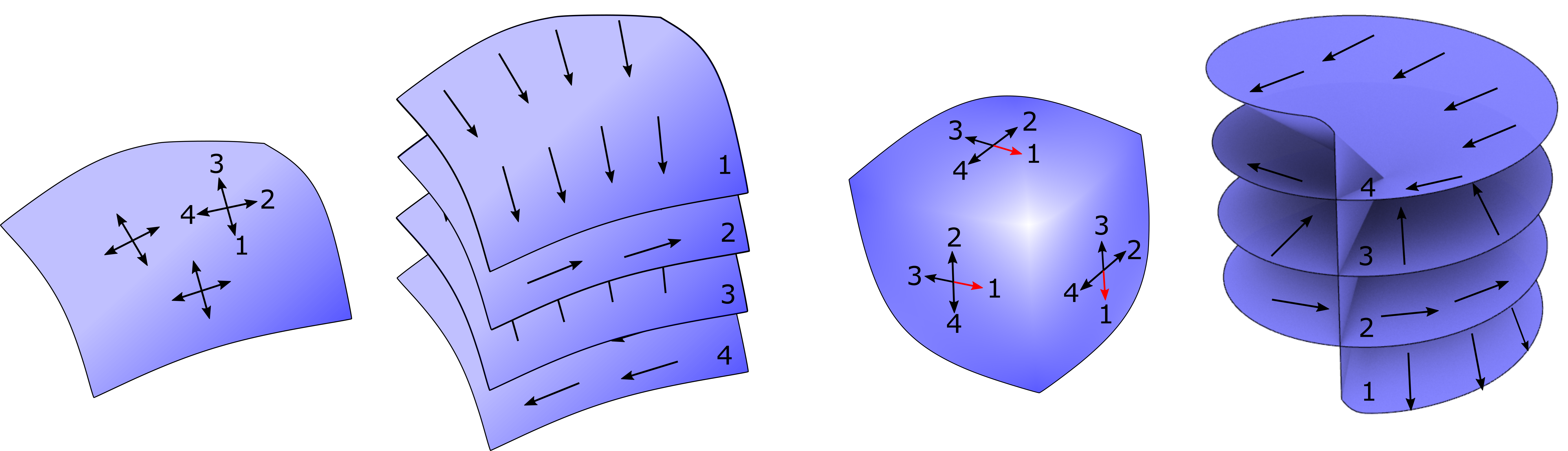 |
|
4-direction frame fields and the corresponding cover spaces. (a)&(b): a field without singular vertex and the four separate sheets of the cover space. (c)&(d): a field with a singular vertex on the cube-corner shaped surface and the four sheets of cover space that are connected and coincide at the singular vertex.
We use the cover space to organize the feature maps: on each sheet of the cover space, the vector field defines canonical reference frames, and a feature map is defined and convoluted with the trainable kernels that are aligned by the reference frames.
Different sheets of the cover space share the trainable kernels.
|
| |
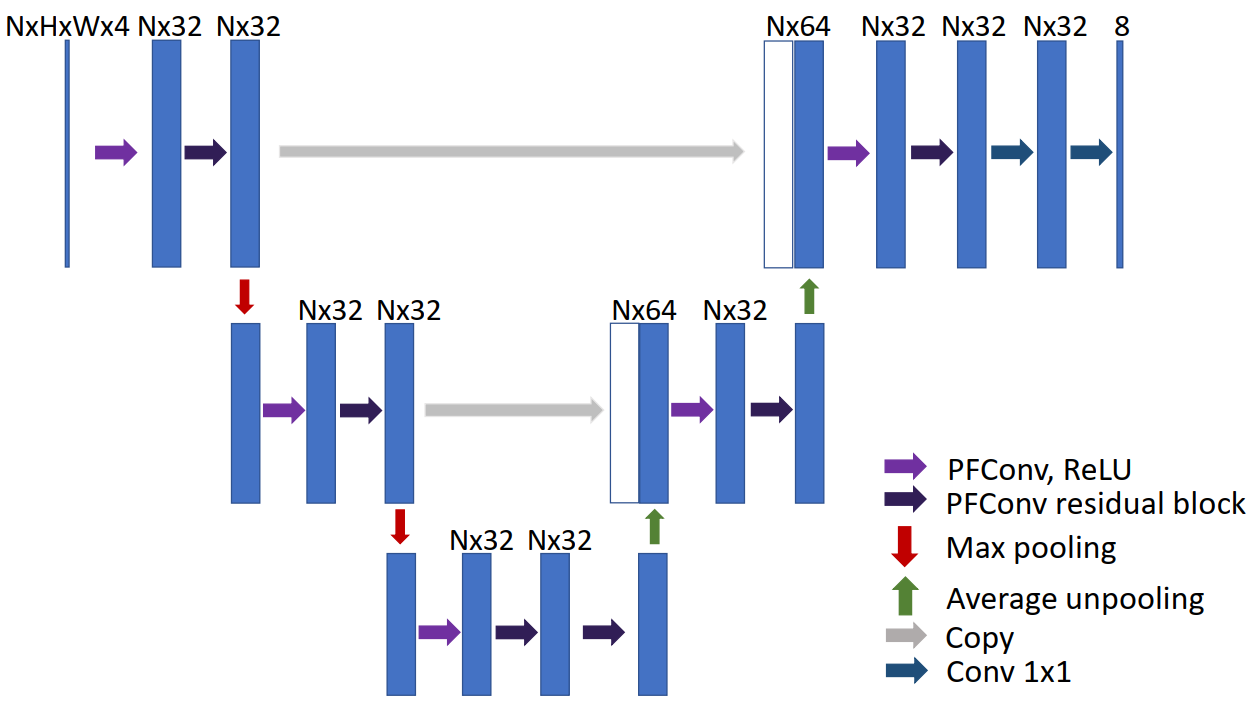 |
|
A U-Net structure built with our PFCNN framework used for the human body segmentation task. Our surface convolution fully supports various CNN structures like ResNet and U-Net. The feature maps for different cover space branches are in parallel and finally reduced into one map before output. In this figure, N is the number of branches (or frame axes).
|
| |
| Results |
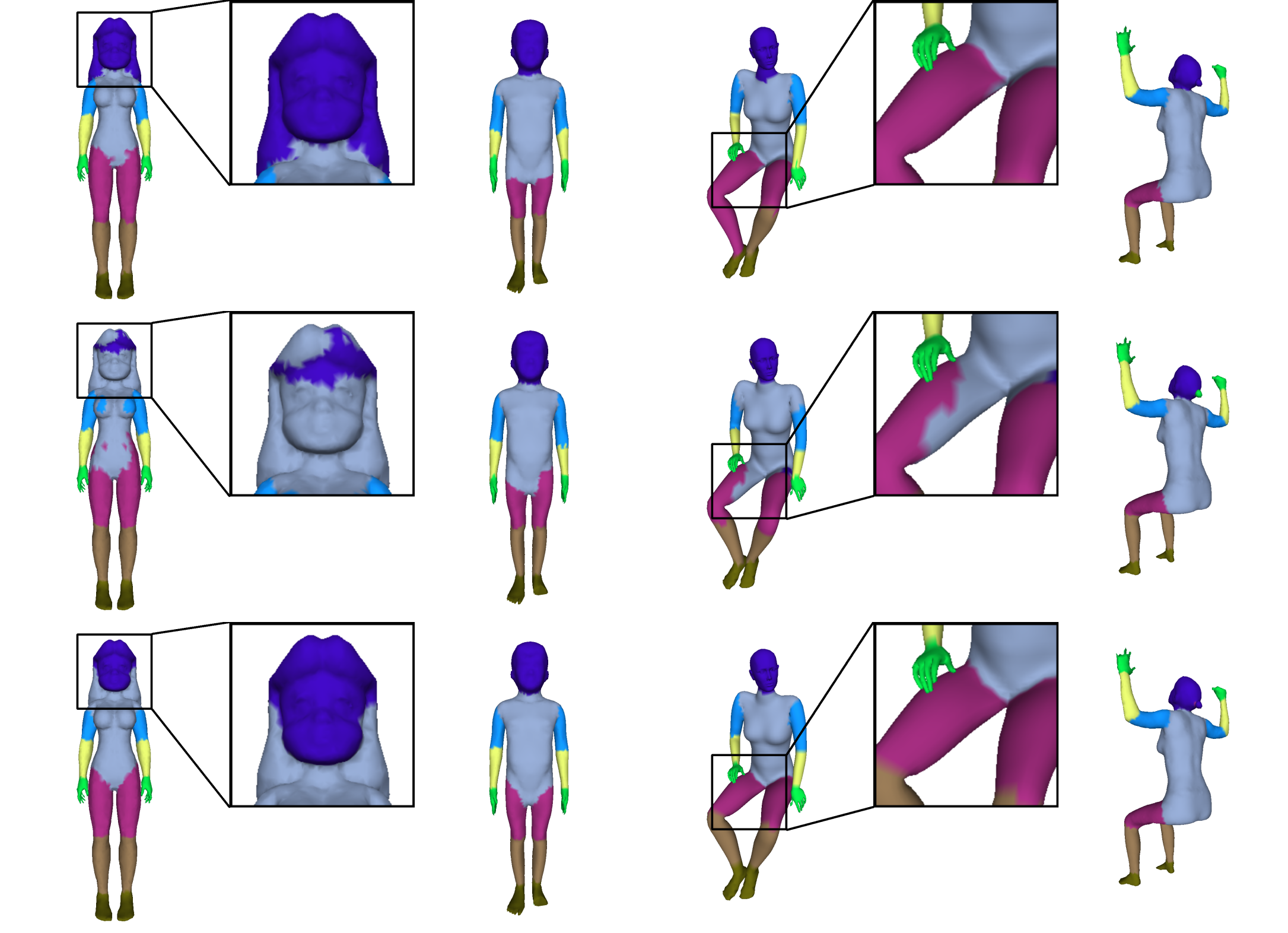 |
|
Visualization of human body segmentation results. From top to bottom: the ground truth labeling, the results by MDGCNN, and our results. We can see that our results are more accurate and consistent.
|
| |
 |
|
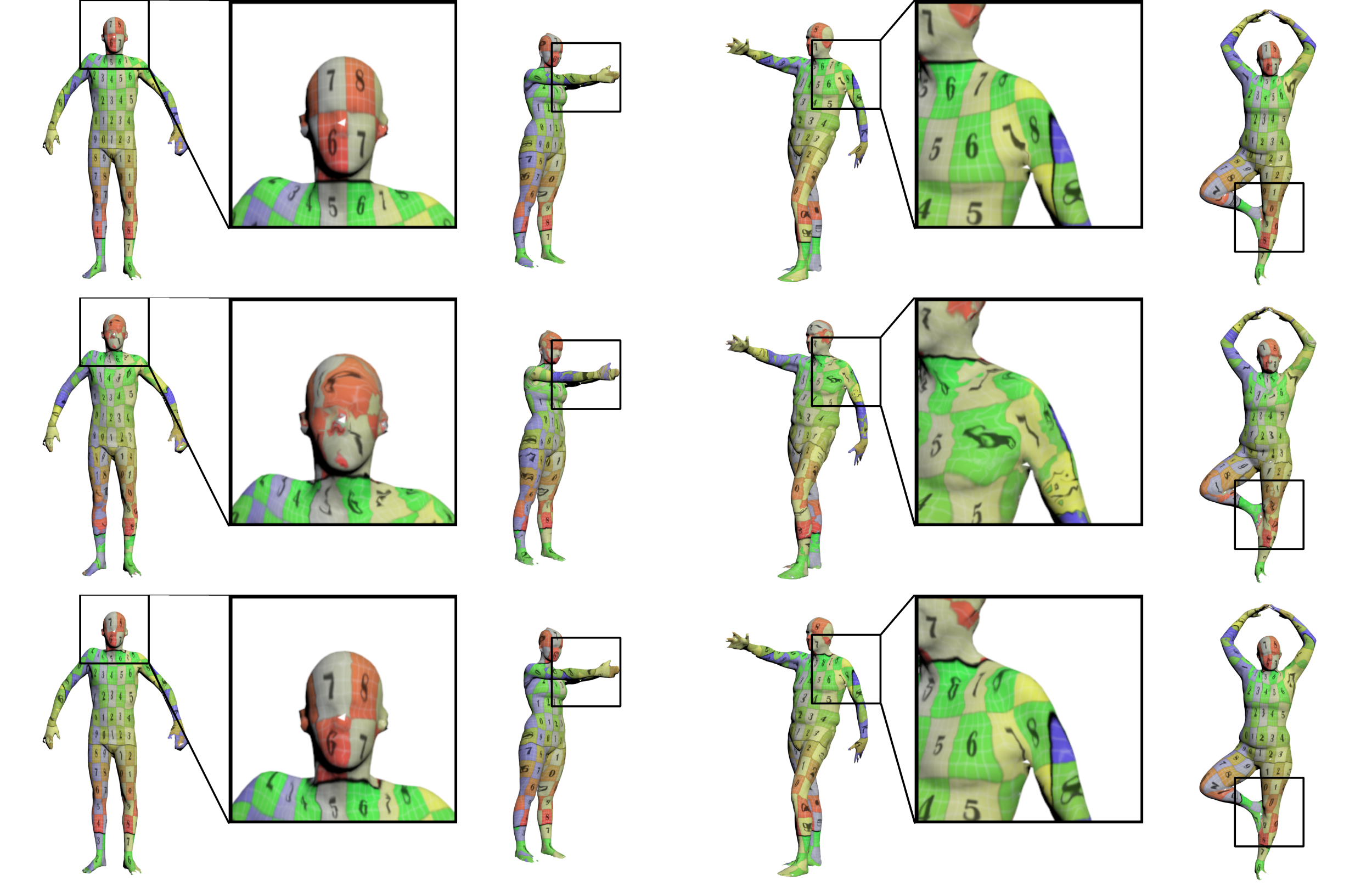
Visualization of human body registration results through texture mapping. From top to bottom: the ground truth registration, the results by MDGCNN, and our results. On these incomplete FAUST scan meshes with diverse genus, our results show higher accuracy and robustness.
|
| |
 |
|
Scannet scene segmentation results. From left to right: the ground truth labels with unkonwn regions marked in dark, the results by TextureNet, and our results. Our results have more regular segmentations and predict reasonable labels even for the unkown regions.
|
| |
| Note: An earlier preprint version of the paper was posted at Arxiv https://arxiv.org/pdf/1808.04952.pdf. |
| |
| |
| ©Hao Pan. Last update: March 19, 2020. |